Importar varias hojas Excel en R
Cuando trabajamos con diferentes fuentes de datos, nos podemos encontrar con tablas distrubidas sobre varias hojas de Excel. En este post vamos a importar la temperatura media diaria de Madrid y Berlín que se encuentra en dos archvios de Excel con hojas para cada año entre 2000 y 2005: descarga.
Paquetes
En este post usaremos los siguientes paquetes:
| Paquete | Descripción |
|---|---|
| tidyverse | Conjunto de paquetes (visualización y manipulación de datos): ggplot2, dplyr, purrr,etc. |
| fs | Proporciona una interfaz uniforme y multiplataforma para las operaciones del sistema de archivos |
| readxl | Importar archivos Excel |
#instalamos los paquetes si hace falta
if(!require("tidyverse")) install.packages("tidyverse")
if(!require("fs")) install.packages("fs")
if(!require("readxl")) install.packages("readxl")
#paquetes
library(tidyverse)
library(fs)
library(readxl)Por defecto, la función read_excel() importa la primera hoja. Para importar una hoja diferente es necesario indicarlo con el argumento sheet o bien el número o el nombre (segundo argumento).
#importar primera hoja
read_excel("madrid_temp.xlsx")## # A tibble: 366 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 5.4 2000
## 2 2000-01-02 00:00:00 5 2000
## 3 2000-01-03 00:00:00 3.5 2000
## 4 2000-01-04 00:00:00 4.3 2000
## 5 2000-01-05 00:00:00 0.6 2000
## 6 2000-01-06 00:00:00 3.8 2000
## 7 2000-01-07 00:00:00 6.2 2000
## 8 2000-01-08 00:00:00 5.4 2000
## 9 2000-01-09 00:00:00 5.5 2000
## 10 2000-01-10 00:00:00 4.8 2000
## # ... with 356 more rows#importar hoja 3
read_excel("madrid_temp.xlsx", 3)## # A tibble: 365 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2002-01-01 00:00:00 8.7 2002
## 2 2002-01-02 00:00:00 7.4 2002
## 3 2002-01-03 00:00:00 8.5 2002
## 4 2002-01-04 00:00:00 9.2 2002
## 5 2002-01-05 00:00:00 9.3 2002
## 6 2002-01-06 00:00:00 7.3 2002
## 7 2002-01-07 00:00:00 5.4 2002
## 8 2002-01-08 00:00:00 5.6 2002
## 9 2002-01-09 00:00:00 6.8 2002
## 10 2002-01-10 00:00:00 6.1 2002
## # ... with 355 more rowsLa función excel_sheets() permite extraer los nombres de las hojas.
path <- "madrid_temp.xlsx"
path %>%
excel_sheets()## [1] "2000" "2001" "2002" "2003" "2004" "2005"El resultado nos indica que en cada hoja encontramos un año de los datos desde 2000 a 2005. La función más importante para leer múltiples hojas es map() del paquete {purrr} que forma parte de la colección de paquetes {tidyverse}. map() permite aplicar una función a cada elemento de un vector o lista.
path <- "madrid_temp.xlsx"
mad <- path %>%
excel_sheets() %>%
set_names() %>%
map(read_excel,
path = path)
str(mad)## List of 6
## $ 2000: tibble [366 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:366], format: "2000-01-01" "2000-01-02" ...
## ..$ ta : num [1:366] 5.4 5 3.5 4.3 0.6 3.8 6.2 5.4 5.5 4.8 ...
## ..$ yr : num [1:366] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
## $ 2001: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2001-01-01" "2001-01-02" ...
## ..$ ta : num [1:365] 8.2 8.8 7.5 9.2 10 9 5.5 4.6 3 7.9 ...
## ..$ yr : num [1:365] 2001 2001 2001 2001 2001 ...
## $ 2002: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2002-01-01" "2002-01-02" ...
## ..$ ta : num [1:365] 8.7 7.4 8.5 9.2 9.3 7.3 5.4 5.6 6.8 6.1 ...
## ..$ yr : num [1:365] 2002 2002 2002 2002 2002 ...
## $ 2003: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2003-01-01" "2003-01-02" ...
## ..$ ta : num [1:365] 9.4 10.8 9.7 9.2 6.3 6.6 3.8 6.4 4.3 3.4 ...
## ..$ yr : num [1:365] 2003 2003 2003 2003 2003 ...
## $ 2004: tibble [366 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:366], format: "2004-01-01" "2004-01-02" ...
## ..$ ta : num [1:366] 6.6 5.9 7.8 8.1 6.4 5.7 5.2 6.9 11.8 12.2 ...
## ..$ yr : num [1:366] 2004 2004 2004 2004 2004 ...
## $ 2005: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2005-01-01" "2005-01-02" ...
## ..$ ta : num [1:365] 7.1 7.8 6.4 5.6 4.4 6.8 7.4 6 5.2 4.2 ...
## ..$ yr : num [1:365] 2005 2005 2005 2005 2005 ...El resultado es una lista nombrada con el nombre de cada hoja que contiene el data.frame. Dado que se trata de la misma tabla en todas las hojas, podríamos usar la función bind_rows(), no obstante, existe una variante de map()que directamente nos une todas las tablas por fila: map_df(). Si fuese necesario unir por columna se debería usar map_dfc().
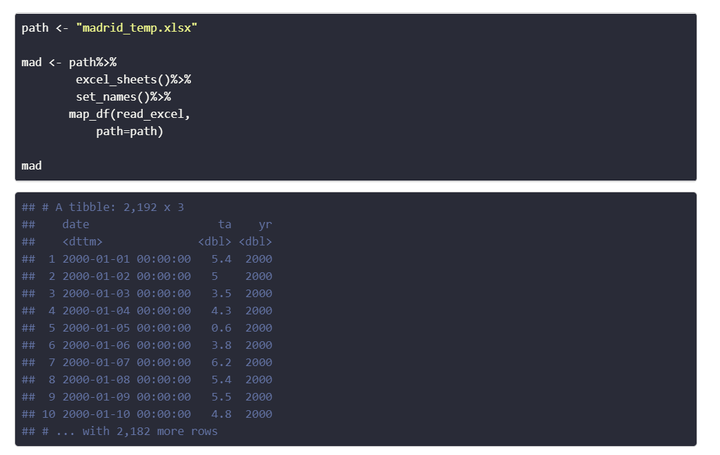
path <- "madrid_temp.xlsx"
mad <- path %>%
excel_sheets() %>%
set_names() %>%
map_df(read_excel,
path = path)
mad## # A tibble: 2,192 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 5.4 2000
## 2 2000-01-02 00:00:00 5 2000
## 3 2000-01-03 00:00:00 3.5 2000
## 4 2000-01-04 00:00:00 4.3 2000
## 5 2000-01-05 00:00:00 0.6 2000
## 6 2000-01-06 00:00:00 3.8 2000
## 7 2000-01-07 00:00:00 6.2 2000
## 8 2000-01-08 00:00:00 5.4 2000
## 9 2000-01-09 00:00:00 5.5 2000
## 10 2000-01-10 00:00:00 4.8 2000
## # ... with 2,182 more rowsEn nuestro caso tenemos una columna en cada hoja (año, pero también la fecha) que diferencia cada tabla. Si no fuera el caso, deberíamos usar el nombre de las hojas como nueva columna al unir todas. En bind_rows() puede hacerse con el argumento .id asignando un nombre para la columna. Lo mismo valdría para map_df().
path <- "madrid_temp.xlsx"
mad <- path %>%
excel_sheets() %>%
set_names() %>%
map_df(read_excel,
path = path,
.id = "yr2")
str(mad)## tibble [2,192 x 4] (S3: tbl_df/tbl/data.frame)
## $ yr2 : chr [1:2192] "2000" "2000" "2000" "2000" ...
## $ date: POSIXct[1:2192], format: "2000-01-01" "2000-01-02" ...
## $ ta : num [1:2192] 5.4 5 3.5 4.3 0.6 3.8 6.2 5.4 5.5 4.8 ...
## $ yr : num [1:2192] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...¿Pero cómo importamos múltiples archivos de Excel?
Para ello, primero debemos conocer la función dir_ls() del paquete {fs}. Es cierto que existe la función dir() de R Base, pero las ventajas del reciente paquete son varias, pero especialmente es la compatibilidad con la colección de {tidyverse}.
dir_ls()## berlin_temp.xlsx featured.png index.es.html index.es.Rmd
## index.es.Rmd.lock~ index.es_files madrid_temp.xlsx#podemos filtrar los archivos que queremos
dir_ls(regexp = "xlsx") ## berlin_temp.xlsx madrid_temp.xlsxImportamos los dos archivos de Excel que tenemos.
#sin unir
dir_ls(regexp = "xlsx")%>%
map(read_excel)## $berlin_temp.xlsx
## # A tibble: 366 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 1.2 2000
## 2 2000-01-02 00:00:00 3.6 2000
## 3 2000-01-03 00:00:00 5.7 2000
## 4 2000-01-04 00:00:00 5.1 2000
## 5 2000-01-05 00:00:00 2.2 2000
## 6 2000-01-06 00:00:00 1.8 2000
## 7 2000-01-07 00:00:00 4.2 2000
## 8 2000-01-08 00:00:00 4.2 2000
## 9 2000-01-09 00:00:00 4.2 2000
## 10 2000-01-10 00:00:00 1.7 2000
## # ... with 356 more rows
##
## $madrid_temp.xlsx
## # A tibble: 366 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 5.4 2000
## 2 2000-01-02 00:00:00 5 2000
## 3 2000-01-03 00:00:00 3.5 2000
## 4 2000-01-04 00:00:00 4.3 2000
## 5 2000-01-05 00:00:00 0.6 2000
## 6 2000-01-06 00:00:00 3.8 2000
## 7 2000-01-07 00:00:00 6.2 2000
## 8 2000-01-08 00:00:00 5.4 2000
## 9 2000-01-09 00:00:00 5.5 2000
## 10 2000-01-10 00:00:00 4.8 2000
## # ... with 356 more rows#uniendo con una nueva columna
dir_ls(regexp = "xlsx")%>%
map_df(read_excel, .id = "city")## # A tibble: 732 x 4
## city date ta yr
## <chr> <dttm> <dbl> <dbl>
## 1 berlin_temp.xlsx 2000-01-01 00:00:00 1.2 2000
## 2 berlin_temp.xlsx 2000-01-02 00:00:00 3.6 2000
## 3 berlin_temp.xlsx 2000-01-03 00:00:00 5.7 2000
## 4 berlin_temp.xlsx 2000-01-04 00:00:00 5.1 2000
## 5 berlin_temp.xlsx 2000-01-05 00:00:00 2.2 2000
## 6 berlin_temp.xlsx 2000-01-06 00:00:00 1.8 2000
## 7 berlin_temp.xlsx 2000-01-07 00:00:00 4.2 2000
## 8 berlin_temp.xlsx 2000-01-08 00:00:00 4.2 2000
## 9 berlin_temp.xlsx 2000-01-09 00:00:00 4.2 2000
## 10 berlin_temp.xlsx 2000-01-10 00:00:00 1.7 2000
## # ... with 722 more rowsAhora bien, en este caso sólo importamos la primera hoja de cada archivo Excel. Para resolver este problema, debemos crear nuestra propia función. En esta función hacemos lo que hicimos previamente de forma individual.
read_multiple_excel <- function(path) {
path %>%
excel_sheets() %>%
set_names() %>%
map_df(read_excel, path = path)
}Aplicamos nuestra función creada para importar múltiples hojas de varios archivos Excel.
#por separado
data <- dir_ls(regexp = "xlsx") %>%
map(read_multiple_excel)
str(data)## List of 2
## $ berlin_temp.xlsx: tibble [2,192 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:2192], format: "2000-01-01" "2000-01-02" ...
## ..$ ta : num [1:2192] 1.2 3.6 5.7 5.1 2.2 1.8 4.2 4.2 4.2 1.7 ...
## ..$ yr : num [1:2192] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
## $ madrid_temp.xlsx: tibble [2,192 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:2192], format: "2000-01-01" "2000-01-02" ...
## ..$ ta : num [1:2192] 5.4 5 3.5 4.3 0.6 3.8 6.2 5.4 5.5 4.8 ...
## ..$ yr : num [1:2192] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...#unir todas
data_df <- dir_ls(regexp = "xlsx") %>%
map_df(read_multiple_excel,
.id = "city")
str(data_df)## tibble [4,384 x 4] (S3: tbl_df/tbl/data.frame)
## $ city: chr [1:4384] "berlin_temp.xlsx" "berlin_temp.xlsx" "berlin_temp.xlsx" "berlin_temp.xlsx" ...
## $ date: POSIXct[1:4384], format: "2000-01-01" "2000-01-02" ...
## $ ta : num [1:4384] 1.2 3.6 5.7 5.1 2.2 1.8 4.2 4.2 4.2 1.7 ...
## $ yr : num [1:4384] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...![]()