Visualizar el crecimiento urbano
La Dirección General del Catastro de España dispone de información espacial de toda la edificación a excepción del País Vasco y Navarra. Este conjunto de datos forma parte de la implantación de INSPIRE, la Infraestructura de Información Espacial en Europa. Más información podemos encontrar aquí. Utilizaremos los enlaces (urls) en formato ATOM, que es un formato de redifusión de tipo RSS, permitiéndonos obtener el enlace de descarga para cada municipio.
Paquetes
| Paquete | Descripción |
|---|---|
| tidyverse | Conjunto de paquetes (visualización y manipulación de datos): ggplot2, dplyr, purrr,etc. |
| sf | Simple Feature: importar, exportar y manipular datos vectoriales |
| fs | Proporciona una interfaz uniforme y multiplataforma para las operaciones del sistema de archivos |
| lubridate | Fácil manipulación de fechas y tiempos |
| feedeR | Importar formatos de redifusión RSS |
| tmap | Fácil creación de mapas temáticos |
| classInt | Para crear intervalos de clase univariantes |
| sysfonts | Carga familias tipográficas del sistema y de Google |
| showtext | Usar familias tipográficas más fácilmente en gráficos R |
# instalamos los paquetes necesarios
if(!require("tidyverse")) install.packages("tidyverse")
if(!require("feedeR")) install.packages("feedeR")
if(!require("fs")) install.packages("fs")
if(!require("lubridate")) install.packages("lubridate")
if(!require("fs")) install.packages("fs")
if(!require("tmap")) install.packages("tmap")
if(!require("classInt")) install.packages("classInt")
if(!require("showtext")) install.packages("showtext")
if(!require("sysfonts")) install.packages("sysfonts")
if(!require("rvest")) install.packages("rvest")
# cargamos los paquetes
library(feedeR)
library(sf)
library(fs)
library(tidyverse)
library(lubridate)
library(classInt)
library(tmap)
library(rvest)Enlaces de descarga
La primera url nos dará acceso a un listado de provincias, sedes territoriales (no siempre coinciden con la provincia), con nuevos enlaces RSS los cuales incluyen los enlaces finales de descarga para cada municipio. En este caso, descargaremos el edificado de Valencia. Los datos del Catastro se actualizan cada seis meses.
url <- "http://www.catastro.minhap.es/INSPIRE/buildings/ES.SDGC.bu.atom.xml"
# importamos los RSS con enlaces de provincias
prov_enlaces <- feed.extract(url)
str(prov_enlaces) #estructura es lista## List of 4
## $ title : chr "Download service of Buildings. Territorial Office"
## $ link : chr "http://www.catastro.minhap.es/INSPIRE/buildings/ES.SDGC.BU.atom.xml"
## $ updated: POSIXct[1:1], format: "2022-03-14"
## $ items : tibble [52 x 5] (S3: tbl_df/tbl/data.frame)
## ..$ title : chr [1:52] "Territorial office 02 Albacete" "Territorial office 03 Alicante" "Territorial office 04 Almería" "Territorial office 05 Avila" ...
## ..$ date : POSIXct[1:52], format: "2022-03-14" "2022-03-14" ...
## ..$ link : chr [1:52] "http://www.catastro.minhap.es/INSPIRE/buildings/02/ES.SDGC.bu.atom_02.xml" "http://www.catastro.minhap.es/INSPIRE/buildings/03/ES.SDGC.bu.atom_03.xml" "http://www.catastro.minhap.es/INSPIRE/buildings/04/ES.SDGC.bu.atom_04.xml" "http://www.catastro.minhap.es/INSPIRE/buildings/05/ES.SDGC.bu.atom_05.xml" ...
## ..$ description: chr [1:52] "\n\n\t\t " "\n\n\t\t " "\n\n\t\t " "\n\n\t\t " ...
## ..$ hash : chr [1:52] "d21ebb7975e59937" "bdba5e149f09e9d8" "03bcbcc7c5be2e17" "8a154202dd778143" ...# extraemos la tabla con los enlaces
prov_enlaces_tab <- as_tibble(prov_enlaces$items) %>%
mutate(title = repair_encoding(title))## Warning: `html_encoding_repair()` was deprecated in rvest 1.0.0.
## Instead, re-load using the `encoding` argument of `read_html()`
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.## Best guess: UTF-8 (100% confident)prov_enlaces_tab## # A tibble: 52 x 5
## title date link description hash
## <chr> <dttm> <chr> <chr> <chr>
## 1 "Territorial office 02 Albacete" 2022-03-14 00:00:00 http~ "\n\n\t\t ~ d21e~
## 2 "Territorial office 03 Alicante" 2022-03-14 00:00:00 http~ "\n\n\t\t ~ bdba~
## 3 "Territorial office 04 Almería" 2022-03-14 00:00:00 http~ "\n\n\t\t ~ 03bc~
## 4 "Territorial office 05 Avila" 2022-03-14 00:00:00 http~ "\n\n\t\t ~ 8a15~
## 5 "Territorial office 06 Badajoz" 2022-03-14 00:00:00 http~ "\n\n\t\t ~ 7d3f~
## 6 "Territorial office 07 Baleares " 2022-03-14 00:00:00 http~ "\n\n\t\t ~ 9c08~
## 7 "Territorial office 08 Barcelona" 2022-03-14 00:00:00 http~ "\n\n\t\t ~ ff72~
## 8 "Territorial office 09 Burgos " 2022-03-14 00:00:00 http~ "\n\n\t\t ~ b431~
## 9 "Territorial office 10 Cáceres " 2022-03-14 00:00:00 http~ "\n\n\t\t ~ f79c~
## 10 "Territorial office 11 Cádiz " 2022-03-14 00:00:00 http~ "\n\n\t\t ~ d702~
## # ... with 42 more rowsAccedemos y descargamos los datos de Valencia. Para encontrar el enlace final de descarga usamos la función filter() del paquete dplyr buscando el nombre de la sede territorial y posteriormente el nombre del municipio en mayúsculas con la función str_detect() de stringr. La función pull() nos permite extraer una columna de un data.frame.
feed.extract() no importa correctamente en el encoding UTF-8 (Windows). Por eso, en algunas ciudades pueden aparecer una mala codificación de caracteres especiales “Cádiz”. Para subsanar este problema aplicamos la función repair_encoding() del paquete rvest. Áún así pueden surgir problemas que deban corregirse manualmente.
# filtramos la provincia y obtenemos la url RSS
val_atom <- filter(prov_enlaces_tab, str_detect(title, "Valencia")) %>% pull(link)
# importamos la RSS
val_enlaces <- feed.extract(val_atom)
# obtenemos la tabla con los enlaces de descarga
val_enlaces_tab <- val_enlaces$items
val_enlaces_tab <- mutate(val_enlaces_tab, title = repair_encoding(title),
link = repair_encoding(link)) ## Best guess: UTF-8 (80% confident)## Warning in stringi::stri_conv(x, from): the Unicode code point \U0000fffd cannot
## be converted to destination encoding
## Warning in stringi::stri_conv(x, from): the Unicode code point \U0000fffd cannot
## be converted to destination encoding## Best guess: UTF-8 (80% confident)## Warning in stringi::stri_conv(x, from): the Unicode code point \U0000fffd cannot
## be converted to destination encoding
## Warning in stringi::stri_conv(x, from): the Unicode code point \U0000fffd cannot
## be converted to destination encoding# filtramos la tabla con el nombre de la ciudad
val_link <- filter(val_enlaces_tab, str_detect(title, "VALENCIA")) %>% pull(link)
val_link## [1] "http://www.catastro.minhap.es/INSPIRE/Buildings/46/46900-VALENCIA/A.ES.SDGC.BU.46900.zip"Descarga de datos
La descarga se realiza con la función download.file() que únicamente tiene dos argumentos principales, el enlace de descarga y la ruta con el nombre del archivo. En este caso hacemos uso de la función tempfile(), que nos es útil para crear archivos temporales, es decir, archivos que únicamente existen en la memoría RAM por un tiempo determinado.
El archivo que descargamos tiene extensión *.zip, por lo que debemos descomprimirlo con otra función (unzip()), que requiere el nombre del archivo y el nombre de la carpeta donde lo queremos descomprimir. Por último, la función URLencode() codifica una dirección URL que contiene caracteres especiales.
# creamos un archivo temporal
temp <- tempfile()
# descargamos los datos
download.file(URLencode(val_link), temp)
# descomprimimos a una carpeta llamda buildings
unzip(temp, exdir = "buildings_valencia") # cambia el nombre según la ciudadImportar los datos
Para importar los datos utilizamos la función dir_ls() del paquete fs, que nos permite obtener los archivos y carpetas de una ruta concreta al mismo tiempo que filtramos por un patrón de texto (regexp: expresión regular). Aplicamos la función st_read() del paquete sf al archivo espacial de formato Geography Markup Language (GML).
# obtenemos la ruta con el archivo
file_val <- dir_ls("buildings_valencia", regexp = "building.gml") # cambia el nombre de carpeta si es necesario
# importamos los datos
buildings_val <- st_read(file_val)## Reading layer `Building' from data source
## `E:\GitHub\blog_update_2021\content\es\post\2019-11-01-visualizar-crecimiento-urbano\buildings_valencia\A.ES.SDGC.BU.46900.building.gml'
## using driver `GML'
## Simple feature collection with 36284 features and 24 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 720570.9 ymin: 4351286 xmax: 734981.9 ymax: 4382906
## Projected CRS: ETRS89 / UTM zone 30NPreparación de los datos
Únicamente convertimos la columna de la edad del edificio (beginning) en clase Date. La columna de la fecha contiene algunas fechas en formato --01-01 lo que no corresponde a ninguna fecha reconocible. Por eso, reemplazamos el primer - por 0000.
#
buildings_val <- mutate(buildings_val,
beginning = str_replace(beginning, "^-", "0000") %>%
ymd_hms() %>% as_date()
)## Warning: 4 failed to parse.Gráfico de distribución
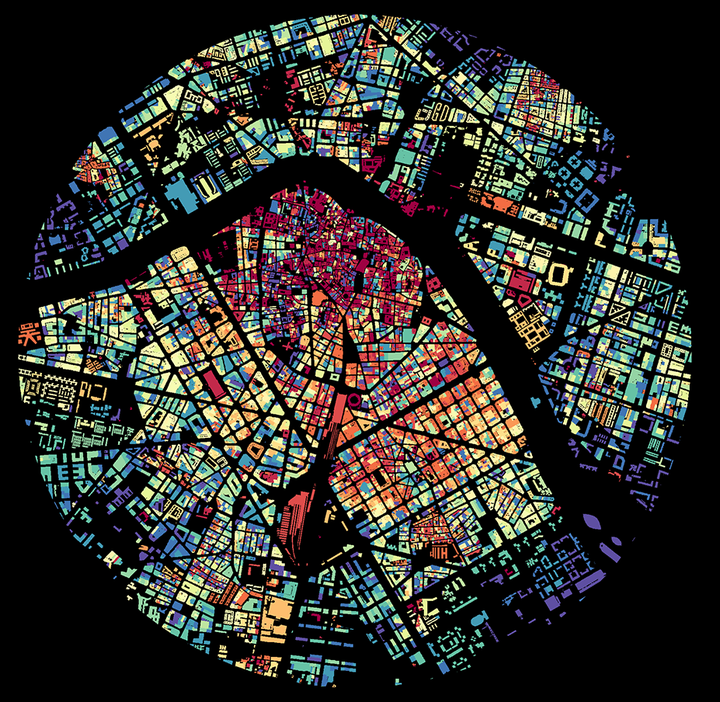
Antes de crear el mapa de la edad del edificado, lo que reflejará el crecimiento urbano, haremos un gráfico de distribución de la fecha de construcción de los edificios. Podremos identificar claramente períodos de expansión urbana. Usaremos el paquete ggplot2 con la geometría de geom_density() para este objetivo. La función font_add_google() del paquete sysfonts nos permite descargar e incluir familias tipográficas de Google.
#descarga de familia tipográfica
sysfonts::font_add_google("Montserrat", "Montserrat")
#usar showtext para familias tipográficas
showtext::showtext_auto() #limitamos al periodo posterior a 1750
filter(buildings_val, beginning >= "1750-01-01") %>%
ggplot(aes(beginning)) +
geom_density(fill = "#2166ac", alpha = 0.7) +
scale_x_date(date_breaks = "20 year",
date_labels = "%Y") +
theme_minimal(base_family = "Montserrat") +
labs(y = "",x = "", title = "Evolución del desarrollo urbano")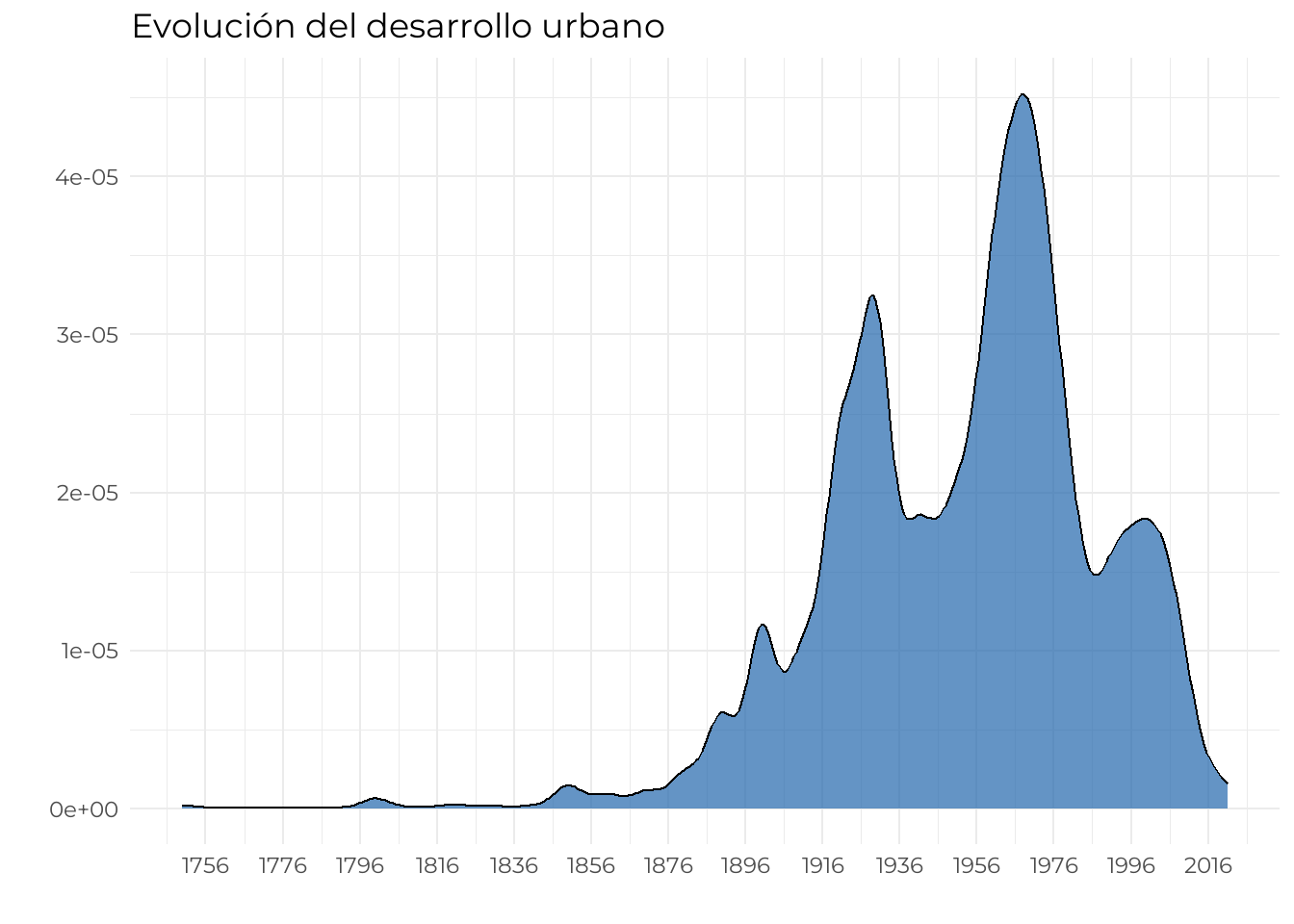
Buffer de 2,5 km de Valencia
Para poder visualizar bien la distribución del crecimiento, limitamos el mapa a un radio de 2,5 km desde el centro de la ciudad. Usamos la función geocode_OSM() del paquete tmaptools para obtener las coordenadas de Valencia en clase sf. Después proyectamos los puntos al sistema que usamos para el edificado (EPSG:25830). La función st_crs() nos devuelve el sistema de coordenadas de un objeto espacial sf. Como último paso creamos con la función st_buffer() un buffer con 2500 m y la intersección con nuestros datos de los edificios. También es posible crear un buffer en forma de un rectángulo indicando el tipo de estilo con el argumento endCapStyle = "SQUARE".
# obtenemos las coordinadas de Valencia
ciudad_point <- tmaptools::geocode_OSM("Valencia",
as.sf = TRUE)
# proyectamos los datos
ciudad_point <- st_transform(ciudad_point, st_crs(buildings_val))
# creamos un buffer
point_bf <- st_buffer(ciudad_point, 2500) # radio de 2500 m
# obtenemos la intersección entre el buffer y la edificación
buildings_val25 <- st_intersection(buildings_val, point_bf)## Warning: attribute variables are assumed to be spatially constant throughout all
## geometriesPreparar los datos para el mapas
Para poder visualizar bien las diferentes épocas de crecimiento, categorizamos el año en 15 grupos empleando cuartiles. También es posible modificar el número de clases o bien el método aplicado (p.j. jenks, fisher, etc), más detalles encontráis en la ayuda ?classIntervals.
#encontrar 15 clases
br <- classIntervals(year(buildings_val25$beginning), 15, "quantile")## Warning in classIntervals(year(buildings_val25$beginning), 15, "quantile"): var
## has missing values, omitted in finding classes#crear etiquetas
lab <- names(print(br, under = "<", over = ">", cutlabels = FALSE))## style: quantile
## < 1890 1890 - 1912 1912 - 1925 1925 - 1930 1930 - 1940 1940 - 1950
## 932 1350 947 594 1703 1054
## 1950 - 1958 1958 - 1962 1962 - 1966 1966 - 1970 1970 - 1973 1973 - 1978
## 1453 1029 1223 1158 1155 1190
## 1978 - 1988 1988 - 1999 > 1999
## 1149 1111 1244#categorizar el año
buildings_val25 <- mutate(buildings_val25,
yr_cl = cut(year(beginning),
br$brks,
labels = lab,
include.lowest = TRUE))Mapa de Valencia
El mapa creamos con el paquete tmap. Es una interesante alternativa a ggplot2. Se trata de un paquete de funciones especializadas en crear mapas temáticos. La filosofía del paquete sigue a la de ggplot2, creando multiples capas con diferentes funciones, que siempre empiezan con tm_* y se combinan con +. La construcción de un mapa con tmap siempre comienza con tm_shape(), donde se definen los datos que queremos dibujar. Luego agregamos la geometría correspondiente al tipo de datos (tm_polygon(), tm_border(), tm_dots() o incluso tm_raster()). La función tm_layout() ayuda a configurar el estilo del mapa.
Cuando necesitamos más colores del máximo permitido por RColorBrewer podemos pasar los colores a la función colorRampPalette(). Esta función interpola para un mayor número más colores de la gama.
#colores
col_spec <- RColorBrewer::brewer.pal(11, "Spectral")
#función de una gama de colores
col_spec_fun <- colorRampPalette(col_spec)
#crear los mapas
tm_shape(buildings_val25) +
tm_polygons("yr_cl",
border.col = "transparent",
palette = col_spec_fun(15), # adapta al número clases
textNA = "Sin dato",
title = "") +
tm_layout(bg.color = "black",
outer.bg.color = "black",
legend.outside = TRUE,
legend.text.color = "white",
legend.text.fontfamily = "Montserrat",
panel.label.fontfamily = "Montserrat",
panel.label.color = "white",
panel.label.bg.color = "black",
panel.label.size = 5,
panel.label.fontface = "bold")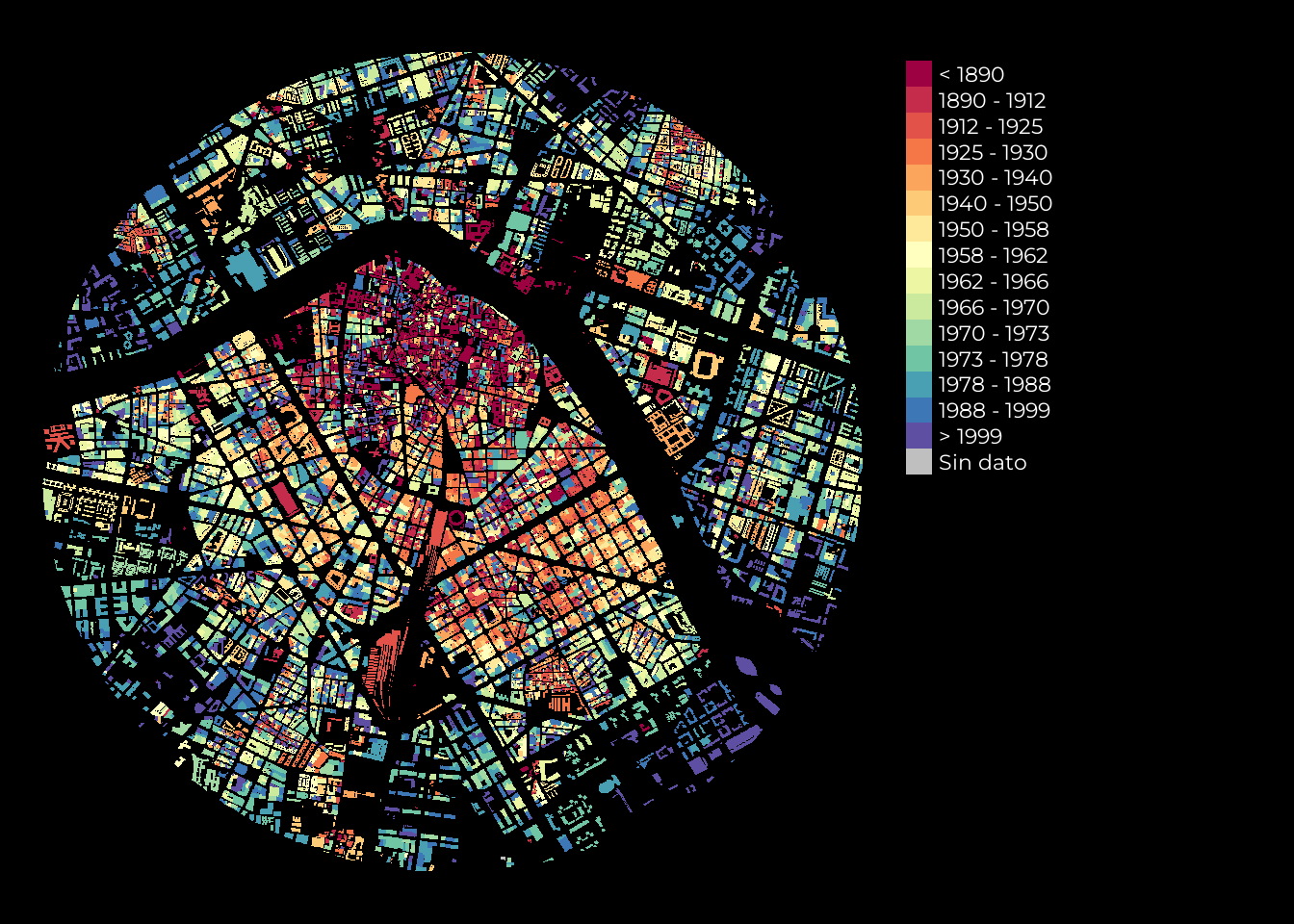
Podemos exportar nuestro mapa usando la función tmap_save("nombre.png", dpi = 300). Recomiendo usar el argumento dpi = 300 para obtener una buena calidad de imagen.
Una alternativa al paquete tmap es ggplot2.
#crear el mapa
ggplot(buildings_val25) +
geom_sf(aes(fill = yr_cl), colour = "transparent") +
scale_fill_manual(values = col_spec_fun(15)) + # adapta al número clases
labs(title = "VALÈNCIA", fill = "") +
guides(fill = guide_legend(keywidth = .7, keyheight = 2.7)) +
theme_void(base_family = "Montserrat") +
theme(panel.background = element_rect(fill = "black"),
plot.background = element_rect(fill = "black"),
legend.justification = .5,
legend.text = element_text(colour = "white", size = 12),
plot.title = element_text(colour = "white", hjust = .5, size = 60,
margin = margin(t = 30)),
plot.caption = element_text(colour = "white",
margin = margin(b = 20), hjust = .5, size = 16),
plot.margin = margin(r = 40, l = 40))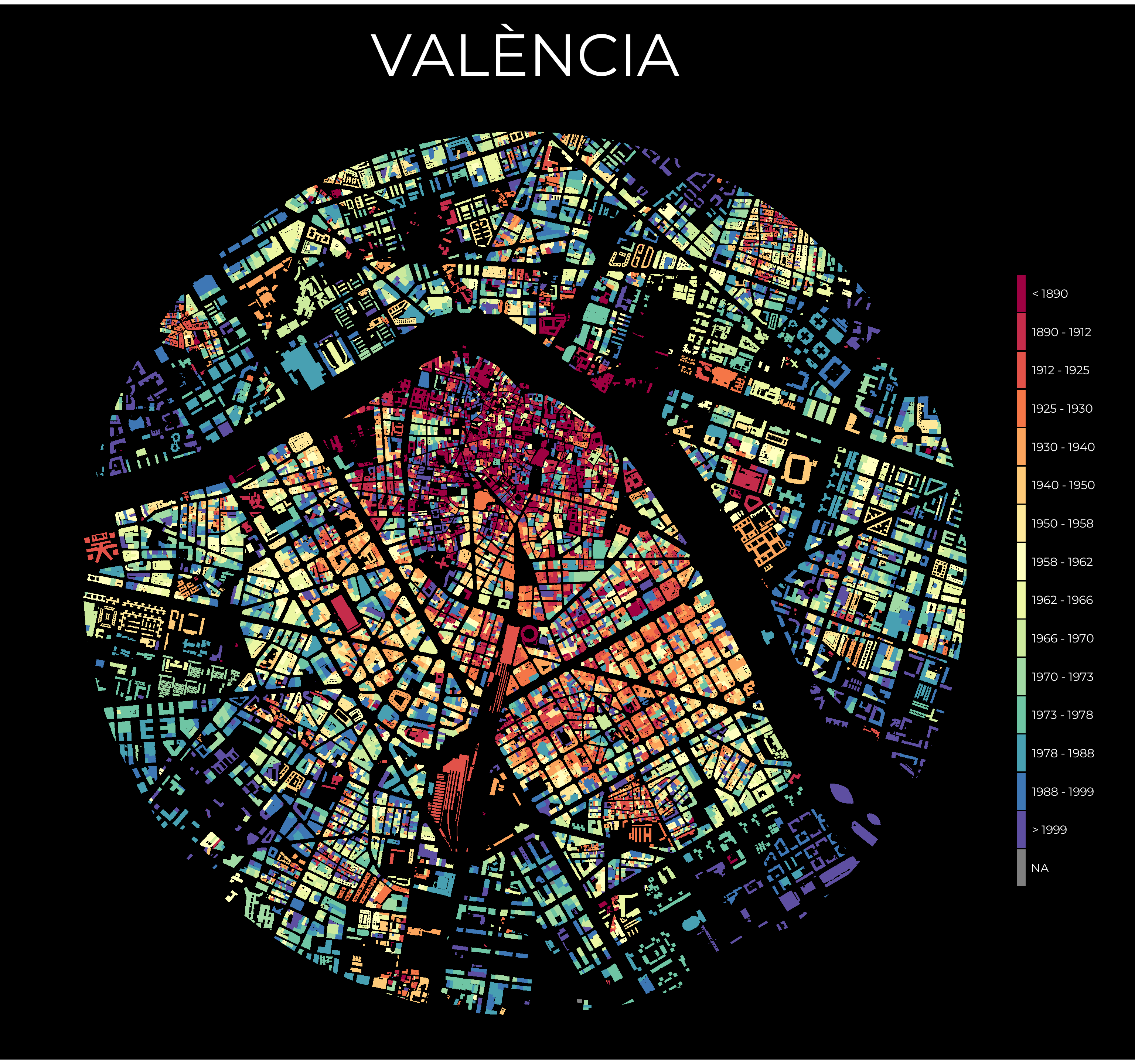
Para exportar el resultado de ggplot podemos emplear la función ggsave("nombre.png").
Mapa dinámico en leaflet
Una ventaja muy interesante es la función tmap_leaflet() del paquete tmap para pasar de forma sencilla un mapa creado en el mismo marco a leaflet.
#mapa tmap de Santiago
m <- tm_shape(buildings_val25) +
tm_polygons("yr_cl",
border.col = "transparent",
palette = col_spec_fun(15), # adapta al número clases
textNA = "Without data",
title = "")
#mapa dinámico
tmap_leaflet(m)![]()