Mapa dasimétrico bivariante
Consideraciones iniciales
Una desventaja de los mapas coropletas es que estos suelen distorsionar la relación entre la verdadera geografía subyacente y la variable representada. Se debe a que las divisiones administrativas no suelen coincidir con la realidad geográfica, donde la gente vive. Además, grandes áreas aparentan tener un peso con poca población que no tienen realmente. Para reflejar mejor la realidad se hace uso de distribuciones más realista de la población como puede ser el uso de suelo. Con técnicas de Sistemas de Información Geográfica es posible redistribuir la variable de interés en función de una variable a menor unidad espacial.
Cuando disponemos de datos de puntos, el proceso de redistribución simplemente es recortar áreas de puntos con población a base del uso de suelo, normalmente clasificado como urbano. En caso de polígonos también podríamos recortar con polígonos de uso de suelo, pero una alternativa interesante son los mismos datos en formato raster. Veremos cómo podemos realizar un mapa dasimétrico usando datos raster con una resolución de 100 m. En este post usaremos datos de secciones censales de la renta media y el índice de Gini de España. No sólo haremos un mapa dasimétrico, sino también bivariante, representando con dos gamas de colores ambas variables en el mismo mapa.
Paquetes
En este post usaremos los siguientes paquetes:
| Paquete | Descripción |
|---|---|
| tidyverse | Conjunto de paquetes (visualización y manipulación de datos): ggplot2, dplyr, purrr,etc. |
| patchwork | Simple gramática para combinar ggplots separados en el mismo gráfico |
| raster | Importar, exportar y manipular raster |
| sf | Simple Feature: importar, exportar y manipular datos vectoriales |
| biscale | Herramientas y paletas para mapeo temático bivariado |
| sysfonts | Cargar fuentes en R |
| showtext | Usar fuentes más fácilmente en gráficos R |
# instalamos los paquetes si hace falta
if(!require("tidyverse")) install.packages("tidyverse")
if(!require("patchwork")) install.packages("patchwork")
if(!require("sf")) install.packages("sf")
if(!require("raster")) install.packages("raster")
if(!require("biscale")) install.packages("biscale")
if(!require("sysfonts")) install.packages("sysfonts")
if(!require("showtext")) install.packages("showtext")
# paquetes
library(tidyverse)
library(sf)
library(readxl)
library(biscale)
library(patchwork)
library(raster)
library(sysfonts)
library(showtext)
library(raster)Preparación
Datos
Primero descargamos todos los datos necesarios. Con excepción de los datos CORINE Land Cover (~200 MB), se pueden obtener los datos almacenados en este blog directamente vía los enlaces indicados .
- CORINE Land Cover 2018 (geotiff): COPERNICUS
- Datos de renta e índice Gini (excel) [INE]: descarga
- Límites censales de España (vectorial) [INE]: descarga
Importar
Lo primero que hacemos es importar el raster del uso de suelo, los datos de renta e índice de Gini y los límites censales.
# raster de CORINE LAND COVER 2018
urb <- raster("U2018_CLC2018_V2020_20u1.tif")
# datos de renta y Gini
renta <- read_excel("30824.xlsx")
gini <- read_excel("37677.xlsx")
# límites censales del INE
limits <- read_sf("SECC_CE_20200101.shp") Usos de suelo
En este primer paso filtramos las secciones censales para obtener aquellas de la Comunidad Autónoma de Madrid, y creamos los límites municipales. Para disolver los polígonos de secciones censales aplicamos la función group_by() en combinación con summarise().
# filtramos la Comunidad Autónoma de Madrid
limits <- filter(limits, NCA == "Comunidad de Madrid")
# obtenemos los límites municipales
mun_limit <- group_by(limits, CUMUN) %>% summarise()En el siguiente paso recortamos el raster de uso de suelo con los límites de Madrid. Recomiendo usar siempre primero la función crop() y después mask(), la primera recorta a la extensión requerida y la segunda enmascara. Posteriormente, eliminamos todos los valores que correspondan a 1 o 2 (urbano continuo, discontinuo). Por último, proyectamos el raster.
# proyectamos los límites
limits_prj <- st_transform(limits, projection(urb))
# acortamos y enmascaramos
urb_mad <- crop(urb, limits_prj) %>%
mask(limits_prj)
# eliminamos píxeles no urbanos
urb_mad[!urb_mad %in% 1:2] <- NA
# plot del raster
plot(urb_mad)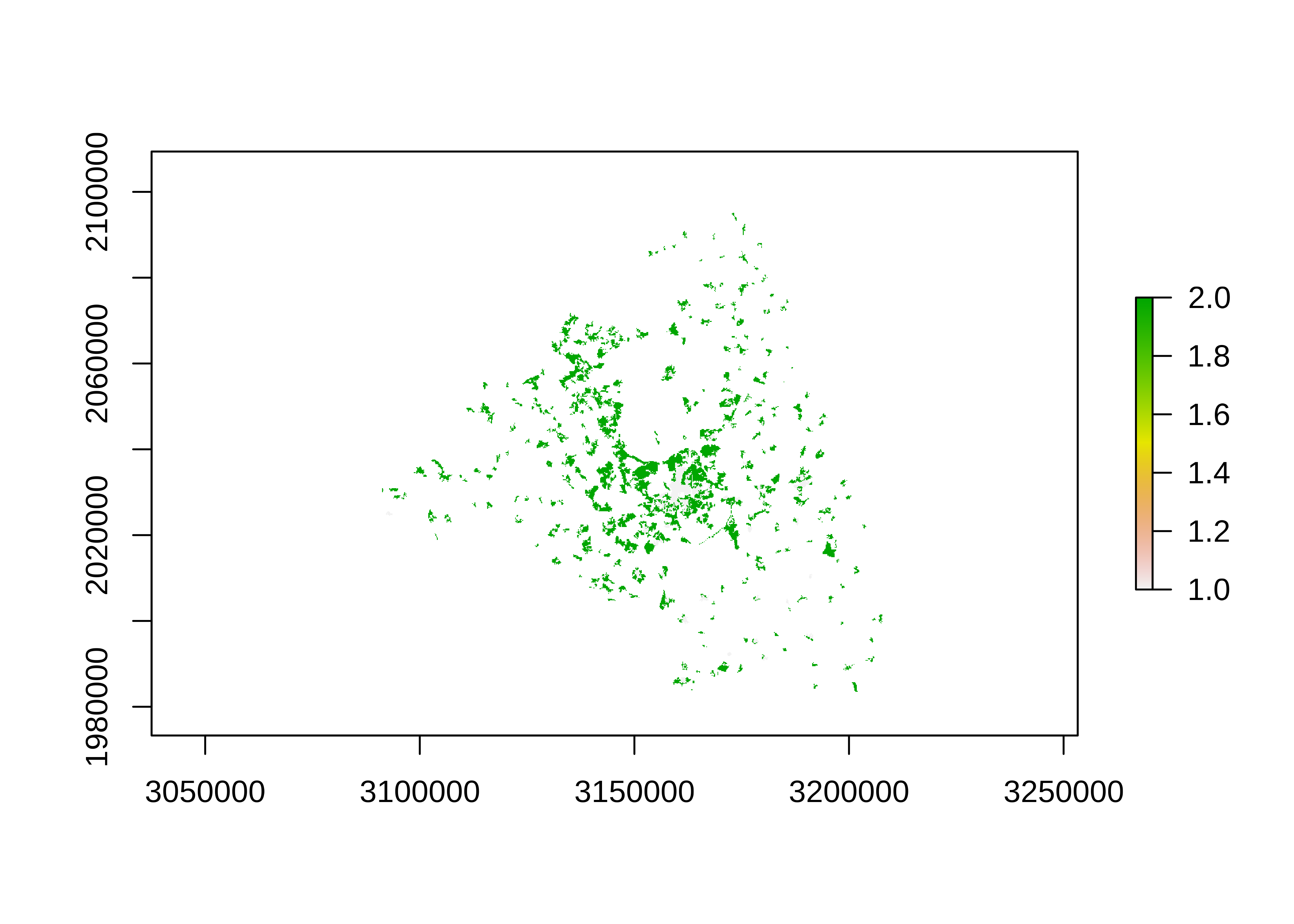
# proyectamos
urb_mad <- projectRaster(urb_mad, crs = CRS("+proj=longlat +datum=WGS84 +no_defs"))En este siguiente paso, convertimos los datos raster en un objeto sf de puntos.
# transformamos el raster a xyz y objeto sf
urb_mad <- as.data.frame(urb_mad, xy = TRUE, na.rm = TRUE) %>%
st_as_sf(coords = c("x", "y"), crs = 4326)
# añadimos las columnas de las coordinadas
urb_mad <- urb_mad %>% rename(urb = 1) %>% cbind(st_coordinates(urb_mad))Renta media e índice de Gini
El formato de los Excels no coincide con el original del INE, dado que he limpiado el formato antes con el objetivo de hacer más fácil este post. Lo que nos queda es crear una columna con los códigos de las secciones censales y excluir datos que corresponden a otro nivel administrativo.
## datos renta y gini INE
renta_sec <- mutate(renta, NATCODE = str_extract(CUSEC, "[0-9]{5,10}"),
nc_len = str_length(NATCODE),
mun_name = str_remove(CUSEC, NATCODE) %>% str_trim()) %>%
filter(nc_len > 5)
gini_sec <- mutate(gini, NATCODE = str_extract(CUSEC, "[0-9]{5,10}"),
nc_len = str_length(NATCODE),
mun_name = str_remove(CUSEC, NATCODE) %>% str_trim()) %>%
filter(nc_len > 5)En el siguiente paso unimos ambas tablas con las secciones censales usando left_join() y convertimos columnas de interés en modo numérico.
# unimos ambas tablas de renta y Gini con los límites censales
mad <- left_join(limits, renta_sec, by = c("CUSEC"="NATCODE")) %>%
left_join(gini_sec, by = c("CUSEC"="NATCODE"))
# convertimos columnas en numérico
mad <- mutate_at(mad, c(23:27, 30:31), as.numeric)Variable bivariante
Para crear un mapa bivariante debemos construir una única variable que combina diferentes clases de dos variables. Normalmente son tres de cada una lo que lleva a nueve clases en total. En nuestro caso, la renta media y el índice Gini. El paquete biscale incluye funciones auxiliares para llevar a cabo este proceso. Con la función bi_class() creamos esta variable de clasificación usando cuantiles como algoritmo. Dado que en ambas variables encontramos valores ausentes, corregimos aquellas combinaciones entre ambas variables donde aparece un NA.
## creamos clasificación bivariante
mapbivar <- bi_class(mad, GINI_2017, RNMP_2017, style = "quantile", dim = 3) %>%
mutate(bi_class = ifelse(str_detect(bi_class, "NA"), NA, bi_class))
# resultado
head(dplyr::select(mapbivar, GINI_2017, RNMP_2017, bi_class))## Simple feature collection with 6 features and 3 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 415538.9 ymin: 4451487 xmax: 469341.7 ymax: 4552422
## Projected CRS: ETRS89 / UTM zone 30N
## # A tibble: 6 x 4
## GINI_2017 RNMP_2017 bi_class geometry
## <dbl> <dbl> <chr> <MULTIPOLYGON [m]>
## 1 NA NA <NA> (((446007.9 4552348, 446133.7 4552288, 446207.8 ~
## 2 31 13581 2-2 (((460243.8 4487756, 460322.4 4487739, 460279 44~
## 3 30 12407 2-2 (((457392.5 4486262, 457391.6 4486269, 457391.1 ~
## 4 34.3 13779 3-2 (((468720.8 4481374, 468695.5 4481361, 468664.6 ~
## 5 33.5 9176 3-1 (((417140.2 4451736, 416867.5 4451737, 416436.8 ~
## 6 26.2 10879 1-1 (((469251.9 4480826, 469268.1 4480797, 469292.6 ~Terminamos redistribuyendo la variable de desigualdad sobre los píxeles del uso de suelo urbano. La función st_join() une los datos con los puntos del uso de suelo.
## redistribuimos los píxeles urbanos a la desigualdad
mapdasi <- st_join(urb_mad, st_transform(mapbivar, 4326))Construcción del mapa
Leyenda y fuente
Antes de construir ambos mapas debemos crear la leyenda usando la función bi_legend(). En la función definimos los títulos para cada variable, el número de dimensiones y la gama de colores. Por último, añadimos la fuente de Montserrat para los títulos del gráfico final.
# leyenda bivariante
legend2 <- bi_legend(pal = "DkViolet",
dim = 3,
xlab = "Más desigual",
ylab = "Más renta",
size = 9)
#descarga de fuente
font_add_google("Montserrat", "Montserrat")
showtext_auto()Mapa dasimétrico
Este mapa construimos usando geom_tile() para los píxeles y geom_sf() para los límites municipales. Además, será el mapa de la derecha donde ubicamos también la leyenda. Para añadir la leyenda hacemos uso de la función annotation_custom() indicando la posición en las coordenadas geográficas del mapa. El paquete biscale también nos ayuda con la definición del color a través de la función bi_scale_fill().
p2 <- ggplot(mapdasi) +
geom_tile(aes(X, Y,
fill = bi_class),
show.legend = FALSE) +
geom_sf(data = mun_limit,
color = "grey80",
fill = NA,
size = 0.2) +
annotation_custom(ggplotGrob(legend2),
xmin = -3.25, xmax = -2.65,
ymin = 40.55, ymax = 40.95) +
bi_scale_fill(pal = "DkViolet",
dim = 3,
na.value = "grey90") +
labs(title = "dasimétrico", x = "", y ="") +
bi_theme() +
theme(plot.title = element_text(family = "Montserrat", size = 30, face = "bold")) +
coord_sf(crs = 4326)Mapa coropleta
El mapa coropleta se construye de forma similar al mapa anterior con la diferencia de que usamos geom_sf().
p1 <- ggplot(mapbivar) +
geom_sf(aes(fill = bi_class),
colour = NA,
size = .1,
show.legend = FALSE) +
geom_sf(data = mun_limit,
color = "white",
fill = NA,
size = 0.2) +
bi_scale_fill(pal = "DkViolet",
dim = 3,
na.value = "grey90") +
labs(title = "coroplético", x = "", y ="") +
bi_theme() +
theme(plot.title = element_text(family = "Montserrat", size = 30, face = "bold")) +
coord_sf(crs = 4326)Combinar ambos mapas
Con ayuda del paquete patchwork combinamos ambos mapas en una única fila, primero el mapa coropleta y a su derecha el mapa dasimétrico. Más detalles de la gramática que se usa para la combinación de gráficos aquí.
# Combinamos
p <- p1 | p2
p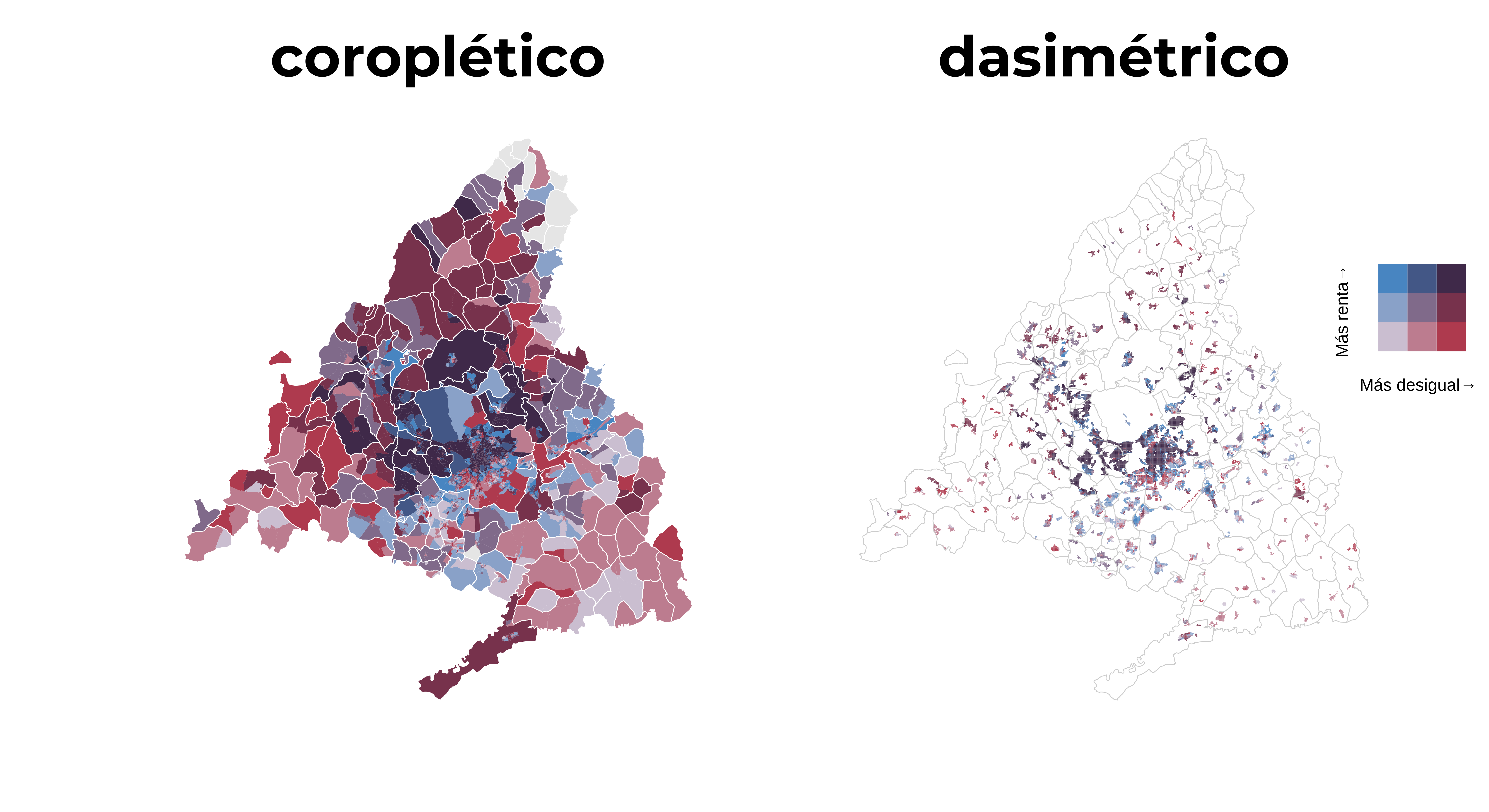
![]()