Import Excel sheets with R
We usually work with different data sources, and sometimes we can find tables distributed over several Excel sheets. In this post we are going to import the average daily temperature of Madrid and Berlin which is found in two Excel files with sheets for each year between 2000 and 2005: download.
Packages
In this post we will use the following packages:
| Packages | Description |
|---|---|
| tidyverse | Collection of packages (visualization, manipulation): ggplot2, dplyr, purrr, etc. |
| fs | Provides a cross-platform, uniform interface to file system operations |
| readxl | Import Excel files |
#install the packages if necessary
if(!require("tidyverse")) install.packages("tidyverse")
if(!require("fs")) install.packages("fs")
if(!require("readxl")) install.packages("readxl")
#load packages
library(tidyverse)
library(fs)
library(readxl)By default, the read_excel() function imports the first sheet. To import a different sheet it is necessary to indicate the number or name with the argument sheet (second argument).
#import first sheet
read_excel("madrid_temp.xlsx")## # A tibble: 366 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 5.4 2000
## 2 2000-01-02 00:00:00 5 2000
## 3 2000-01-03 00:00:00 3.5 2000
## 4 2000-01-04 00:00:00 4.3 2000
## 5 2000-01-05 00:00:00 0.6 2000
## 6 2000-01-06 00:00:00 3.8 2000
## 7 2000-01-07 00:00:00 6.2 2000
## 8 2000-01-08 00:00:00 5.4 2000
## 9 2000-01-09 00:00:00 5.5 2000
## 10 2000-01-10 00:00:00 4.8 2000
## # ... with 356 more rows#import third sheet
read_excel("madrid_temp.xlsx", 3)## # A tibble: 365 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2002-01-01 00:00:00 8.7 2002
## 2 2002-01-02 00:00:00 7.4 2002
## 3 2002-01-03 00:00:00 8.5 2002
## 4 2002-01-04 00:00:00 9.2 2002
## 5 2002-01-05 00:00:00 9.3 2002
## 6 2002-01-06 00:00:00 7.3 2002
## 7 2002-01-07 00:00:00 5.4 2002
## 8 2002-01-08 00:00:00 5.6 2002
## 9 2002-01-09 00:00:00 6.8 2002
## 10 2002-01-10 00:00:00 6.1 2002
## # ... with 355 more rowsThe excel_sheets() function can extract the names of the sheets.
path <- "madrid_temp.xlsx"
path %>%
excel_sheets()## [1] "2000" "2001" "2002" "2003" "2004" "2005"The results are the sheet names and we find the years from 2000 to 2005. The most important function to read multiple sheets is map() of the {purrr} package, which is part of the {tidyverse] collection. map() allows you to apply a function to each element of a vector or list.
path <- "madrid_temp.xlsx"
mad <- path %>%
excel_sheets() %>%
set_names() %>%
map(read_excel,
path = path)
str(mad)## List of 6
## $ 2000: tibble [366 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:366], format: "2000-01-01" "2000-01-02" ...
## ..$ ta : num [1:366] 5.4 5 3.5 4.3 0.6 3.8 6.2 5.4 5.5 4.8 ...
## ..$ yr : num [1:366] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
## $ 2001: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2001-01-01" "2001-01-02" ...
## ..$ ta : num [1:365] 8.2 8.8 7.5 9.2 10 9 5.5 4.6 3 7.9 ...
## ..$ yr : num [1:365] 2001 2001 2001 2001 2001 ...
## $ 2002: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2002-01-01" "2002-01-02" ...
## ..$ ta : num [1:365] 8.7 7.4 8.5 9.2 9.3 7.3 5.4 5.6 6.8 6.1 ...
## ..$ yr : num [1:365] 2002 2002 2002 2002 2002 ...
## $ 2003: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2003-01-01" "2003-01-02" ...
## ..$ ta : num [1:365] 9.4 10.8 9.7 9.2 6.3 6.6 3.8 6.4 4.3 3.4 ...
## ..$ yr : num [1:365] 2003 2003 2003 2003 2003 ...
## $ 2004: tibble [366 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:366], format: "2004-01-01" "2004-01-02" ...
## ..$ ta : num [1:366] 6.6 5.9 7.8 8.1 6.4 5.7 5.2 6.9 11.8 12.2 ...
## ..$ yr : num [1:366] 2004 2004 2004 2004 2004 ...
## $ 2005: tibble [365 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:365], format: "2005-01-01" "2005-01-02" ...
## ..$ ta : num [1:365] 7.1 7.8 6.4 5.6 4.4 6.8 7.4 6 5.2 4.2 ...
## ..$ yr : num [1:365] 2005 2005 2005 2005 2005 ...The result is a named list with the name of each sheet that contains the data.frame. Since it is the same table in all sheets, we could use the function bind_rows(), however, there is a variant of map() that directly joins all the tables by row: map_df(). If it were necessary to join by column, map_dfc() could be used.
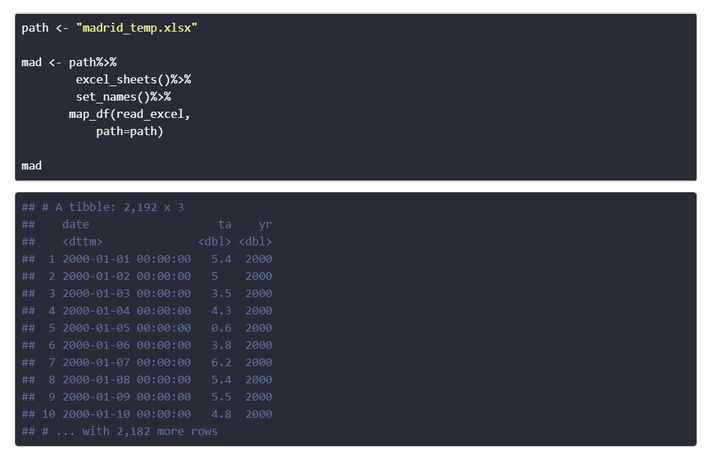
path <- "madrid_temp.xlsx"
mad <- path %>%
excel_sheets() %>%
set_names() %>%
map_df(read_excel,
path = path)
mad## # A tibble: 2,192 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 5.4 2000
## 2 2000-01-02 00:00:00 5 2000
## 3 2000-01-03 00:00:00 3.5 2000
## 4 2000-01-04 00:00:00 4.3 2000
## 5 2000-01-05 00:00:00 0.6 2000
## 6 2000-01-06 00:00:00 3.8 2000
## 7 2000-01-07 00:00:00 6.2 2000
## 8 2000-01-08 00:00:00 5.4 2000
## 9 2000-01-09 00:00:00 5.5 2000
## 10 2000-01-10 00:00:00 4.8 2000
## # ... with 2,182 more rowsIn our case we have a column in each sheet (year, but also the date) that differentiates each table. If it were not the case, we should use the name of the sheets as a new column when joining all of them. In bind_rows() it can be done with the .id argument by assigning a name for the column. The same works for map_df().
path <- "madrid_temp.xlsx"
mad <- path %>%
excel_sheets() %>%
set_names() %>%
map_df(read_excel,
path = path,
.id = "yr2")
str(mad)## tibble [2,192 x 4] (S3: tbl_df/tbl/data.frame)
## $ yr2 : chr [1:2192] "2000" "2000" "2000" "2000" ...
## $ date: POSIXct[1:2192], format: "2000-01-01" "2000-01-02" ...
## $ ta : num [1:2192] 5.4 5 3.5 4.3 0.6 3.8 6.2 5.4 5.5 4.8 ...
## $ yr : num [1:2192] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...But how do we import multiple Excel files?
To do this, first we must know the dir_ls() function from the {fs} package. Indeed, there is the dir() function of R Base, but the advantages of the recent package are several, especially the compatibility with the {tidyverse} collection.
dir_ls()## berlin_temp.xlsx featured.png index.en.html index.en.Rmd
## index.en.Rmd.lock~ index.en_files madrid_temp.xlsx#we can filter the files that we want
dir_ls(regexp = "xlsx") ## berlin_temp.xlsx madrid_temp.xlsxWe import the two Excel files.
#without joining
dir_ls(regexp = "xlsx") %>%
map(read_excel)## $berlin_temp.xlsx
## # A tibble: 366 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 1.2 2000
## 2 2000-01-02 00:00:00 3.6 2000
## 3 2000-01-03 00:00:00 5.7 2000
## 4 2000-01-04 00:00:00 5.1 2000
## 5 2000-01-05 00:00:00 2.2 2000
## 6 2000-01-06 00:00:00 1.8 2000
## 7 2000-01-07 00:00:00 4.2 2000
## 8 2000-01-08 00:00:00 4.2 2000
## 9 2000-01-09 00:00:00 4.2 2000
## 10 2000-01-10 00:00:00 1.7 2000
## # ... with 356 more rows
##
## $madrid_temp.xlsx
## # A tibble: 366 x 3
## date ta yr
## <dttm> <dbl> <dbl>
## 1 2000-01-01 00:00:00 5.4 2000
## 2 2000-01-02 00:00:00 5 2000
## 3 2000-01-03 00:00:00 3.5 2000
## 4 2000-01-04 00:00:00 4.3 2000
## 5 2000-01-05 00:00:00 0.6 2000
## 6 2000-01-06 00:00:00 3.8 2000
## 7 2000-01-07 00:00:00 6.2 2000
## 8 2000-01-08 00:00:00 5.4 2000
## 9 2000-01-09 00:00:00 5.5 2000
## 10 2000-01-10 00:00:00 4.8 2000
## # ... with 356 more rows#joining with a new id column
dir_ls(regexp = "xlsx") %>%
map_df(read_excel, .id = "city")## # A tibble: 732 x 4
## city date ta yr
## <chr> <dttm> <dbl> <dbl>
## 1 berlin_temp.xlsx 2000-01-01 00:00:00 1.2 2000
## 2 berlin_temp.xlsx 2000-01-02 00:00:00 3.6 2000
## 3 berlin_temp.xlsx 2000-01-03 00:00:00 5.7 2000
## 4 berlin_temp.xlsx 2000-01-04 00:00:00 5.1 2000
## 5 berlin_temp.xlsx 2000-01-05 00:00:00 2.2 2000
## 6 berlin_temp.xlsx 2000-01-06 00:00:00 1.8 2000
## 7 berlin_temp.xlsx 2000-01-07 00:00:00 4.2 2000
## 8 berlin_temp.xlsx 2000-01-08 00:00:00 4.2 2000
## 9 berlin_temp.xlsx 2000-01-09 00:00:00 4.2 2000
## 10 berlin_temp.xlsx 2000-01-10 00:00:00 1.7 2000
## # ... with 722 more rowsHowever, in this case we only import the first sheet of each Excel file. To solve this problem, we must create our own function. In this function we do what we previously did individually.
read_multiple_excel <- function(path) {
path %>%
excel_sheets() %>%
set_names() %>%
map_df(read_excel, path = path)
}We apply our created function to import multiple sheets of several Excel files.
#separately
data <- dir_ls(regexp = "xlsx") %>%
map(read_multiple_excel)
str(data)## List of 2
## $ berlin_temp.xlsx: tibble [2,192 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:2192], format: "2000-01-01" "2000-01-02" ...
## ..$ ta : num [1:2192] 1.2 3.6 5.7 5.1 2.2 1.8 4.2 4.2 4.2 1.7 ...
## ..$ yr : num [1:2192] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...
## $ madrid_temp.xlsx: tibble [2,192 x 3] (S3: tbl_df/tbl/data.frame)
## ..$ date: POSIXct[1:2192], format: "2000-01-01" "2000-01-02" ...
## ..$ ta : num [1:2192] 5.4 5 3.5 4.3 0.6 3.8 6.2 5.4 5.5 4.8 ...
## ..$ yr : num [1:2192] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...#joining all data.frames
data_df <- dir_ls(regexp = "xlsx") %>%
map_df(read_multiple_excel,
.id = "city")
str(data_df)## tibble [4,384 x 4] (S3: tbl_df/tbl/data.frame)
## $ city: chr [1:4384] "berlin_temp.xlsx" "berlin_temp.xlsx" "berlin_temp.xlsx" "berlin_temp.xlsx" ...
## $ date: POSIXct[1:4384], format: "2000-01-01" "2000-01-02" ...
## $ ta : num [1:4384] 1.2 3.6 5.7 5.1 2.2 1.8 4.2 4.2 4.2 1.7 ...
## $ yr : num [1:4384] 2000 2000 2000 2000 2000 2000 2000 2000 2000 2000 ...![]()